* 공부용으로 자료 조사한 것들을 토대로 정리한 내용입니다. 틀린 내용이 있다면 댓글 부탁드립니다.
활성화 함수란, 비선형 신경망 모델을 만들기 위해 각 뉴런의 Linear Function(Weighted Sum, Affine Transformation,,,)의 결과값에 적용해 주는 함수이다.
하나를 예로 들면, 딥러닝을 위한 신경망 모델(neural networks)의 각 층(Layer)에서 각 뉴런(Neuron)에 Input Data(x)가 입력되면 Affine function(f(x) = z = wx + b), 활성화함수(g(wx + b))를 통해 Output Data가 출력값으로 나온다. g(f(x))라는 합성함수 형태가 하나의 뉴런 안에서 수행되는 연산이다. 이 출력값을 다음 레이어의 입력값으로 보내주게 된다. 잠시 주의할 점은 만약 모델의 마지막 레이어라면 다음에 보내줄 loss function을 수행하는 레이어에 대한 입력값 형태에 맞게 활성화함수를 사용할수도 있고, 사용하지 않을 수도 있다. 각 목적에 맞게 적용할 수 있는 다양한 활성화 함수들이 있는데, 각 함수들의 목적은 무엇인지, 활성화함수 자체가 왜 필요한지에 대해 아래에서 찬찬히 다루어 보겠다.

우선, 활성화 함수가 도입된 이유는 신경망 모델의 비선형 문제를 해결하기 위해서이다. 여러 개의 선형 layer를 쌓는 것은 여러번의 affine function을 적용해주는 것과 같다. 여러개의 층을 쌓아도, 이는 선형성을 가지기 때문에 결국 하나의 affine function으로도 표현이 가능하여, 하나의 선형 layer를 사용하는 것과 같다. 그러므로 간단한 선형모델로는 선형 문제만 풀 수 있고, 비선형 문제는 결코 해결할 수 없었다. 이 문제를 해결해기 위해서 활성화함수를 적용해주게 된 것이다. 따라서, 활성화 함수에는 비선형 함수들을 사용하게 되는데, 대표적으로 Sigmoid, softmax, tanh, ReLU 등이 있다. 수많은 응용된 함수들이 다양하게 있지만 해당 글에서는 대표적인 4가지의 함수에 대해서 특성과 연산 방법, 그래프에 대한 내용을 담았다.
1. Sigmoid
시그모이드 활성화 함수는 어떤 실수 입력값들이 들어와도 0에서 1사이의 값으로 출력해주는 함수이다. 모델의 목적이 확률값(0~1)을 구해야하는 문제일 때 주로 사용된다. 대표적인 예로는 이진 분류(binary classification)문제를 풀기위한 logistic regression methods (로지스틱 회귀 방법)을 구현해주기 위해 sigmoid를 활용해줄 수 있다. 실제로 로지스틱 함수의 특수한 경우가 시그모이드 함수이다. (로지스틱 함수식에서 K=C=r=1인 경우)
* 참고 링크 : What are the differences between Logistic Function and Sigmoid Function?

* 로지스틱 회귀 : 이항형 종속변수(ex. 이항분포/베르누이분포 - 2가지 범주를 가지는 문제)를 가지고, 독립 변수(입력값)의 선형결합식을 통해 독립 변수와 종속 변수간의 관계를 구체적인 함수로 나타낸다. 이를 분류 예측 모델로써 활용할 수 있다. 3개 이상의 범주는 다항/분화 로지스틱 회귀, 서수 로지스틱 회귀를 사용할 수 있다.
* sigmoid 식 유도방법 : odds(가능성)에 log를 취한 값인 로짓함수의 역함수로써 p(정답일 확률)을 구해줄 수 있다.




2. Softmax
softmax 함수는 다중분류(multi-class classification)문제에 가장 자주 쓰이는 활성화 함수이다. 이진분류에서도 사용 가능하기 때문에 sigmoid 대신 사용해줄 수도 있다. 소프트맥스 결과값도 항상 0과 1사이의 값을 출력해주며, 아래의 식처럼 e를 밑으로 가지고, 이전 layer의 결과값인 class별 z값을 지수로 가지는 값들로 각 class별 확률을 구해주는 방식이다. K는 class 개수이다.

* minibatch로 입력값을 넣을 경우, softmax function의 결과값은 확률행렬이 나오게 된다.
* 다음 단계인 loss function이 CE(Cross Entropy)라면 무조건 확률값을 인풋으로 받아야하기 때문에 sigmoid 또는 softmax함수를 사용해주어야 한다.
3. tanh
쌍곡선 함수(hyperbolic function)의 h와 탄젠트(tangent) 삼각함수의 tan을 따서 tanh는 쌍곡탄젠트(hyperbolic tangent)라고 읽는 활성화 함수가 있다. 시그모이드 함수를 선형변환한 것으로 시그모이드의 기울기 소실 문제를 좀 더 해결하기 위해 고안된 방법이다. -1부터 1까지의 출력값을 가지기 때문에 sigmoid와 비교해서 아래의 두가지 성질을 가진다.
1) sigmoid보다 학습 효율성이 뛰어나다.
2) 출력값의 범위폭이 sigmoid보다 크기 때문에 그레디언트(기울기) 소실 문제가 덜 발생한다. 하지만 이 범위폭도 큰 범위가 아니기 때문에, 기울기 소실 문제가 여전히 존재한다.


4. ReLU
ReLU(렐루)함수는 Rectified Linear Unit의 줄임말로 Rectifier라고 불리기도 한다. 한국어로는 경사 함수, 정류한 선형 유닛, 꺽인 선형 등으로 표현할 수 있다. 최근에 활성화 함수로써 가장 많이 애용되는 함수로 특히 은닉층(hidden layer)에 많이 사용된다.
간단한 계산 방식으로는 입력된 값이 +라면 그 값 그대로를 출력하고, -라면 0을 출력해주는 함수이다. 0을 기준으로 음수인 신호는 차단해버리고, 양수인 신호는 그 값 그대로를 받아들이는 것이다. 그래프는 아래의 사진과 같다.
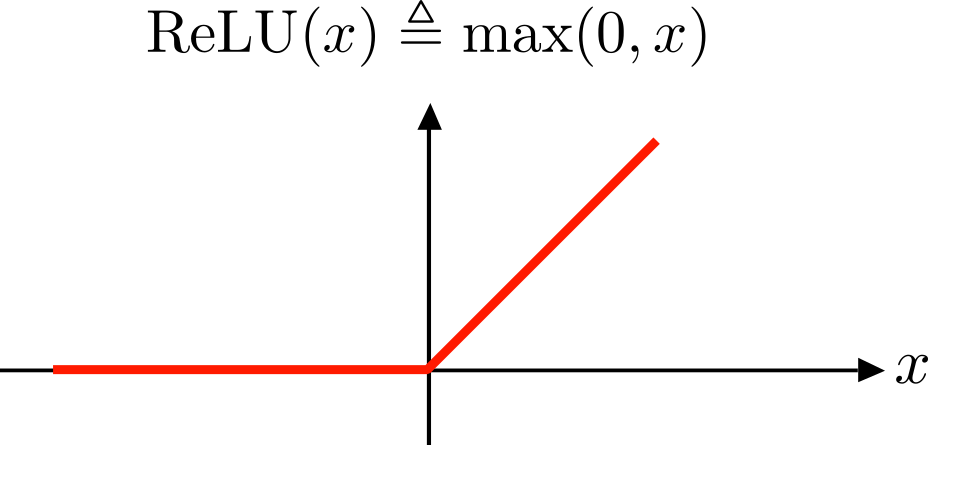
ReLU가 많이 사용되는 이유 중 하나는 양수 입력 값만으로 가중치를 업데이트 하기 때문에 기울기가 0이 되는 기울기 소실 문제를 방지하는데 효과적이라는 것이다. 또한, 음수 대신 0을 사용하고, 많은 뉴런들이 0을 출력하게 되는 희소 활성화(sparse activation)현상에 따라 전체 뉴런에서 필터링된 활성화된 뉴런만을 계산하기 때문에 효율적인 계산량을 가진다. 하지만 이로 인해 몇몇 가중치들이 아예 업데이트 되지않는 Dying ReLU 현상이 발생하여 이를 보완한 Leaky ReLU - max(0.1x, x), PReLU(Parametric ReLU) - max(αx, x), GELU(Gaussian Error Linear Unit), ELU(Exponential Linear Unit) 등의 활성화 함수들이 개발되었다.
해당 글에서는 활성화 함수가 무엇인지, 어떤 용도로 사용하는 것인지에 대해 알아보았다.
또한, 활성화 함수의 아주 유명하고, 기본이 되는 sigmoid, softmax, tanh, relu에 대해서 간략하게 그 특징들을 알아 보았다.
활성화 함수별로 활용되는 용도도 다양하고, 그 장단점도 확실하다.
본인이 어떤 모델을 개발하고 싶은지에 따라 적용해야하는 활성화 함수는 다를 것이다. 모델에서 원하는 결과 값을 얻기 위해서는 각 활성화 함수들의 특징들을 파악하고, 그에 적합한 함수를 적용해보는 과정이 필요할 것이다.
'AI > Fundamental' 카테고리의 다른 글
| 정규화란? Normalization, Regularization 정규화 종류에 대해서 알아보자. (0) | 2023.09.13 |
|---|---|
| LSTM (Long Short-Term Memory) 신경망 모델 공부하기 (0) | 2023.08.28 |
| RNN(Recurrent Neural Network) 순환신경망 공부하기 (2) | 2023.06.14 |
| Confusion Matrix로 분류모델 성능평가 지표(precision, recall, f1-score, accuracy) 구하는 방법 (0) | 2023.01.26 |
| [머신러닝] 학습, 검증, 테스트 데이터 쪼개는 법 : random_split PyTorch), train_test_split(Scikit-learn) (0) | 2022.08.26 |