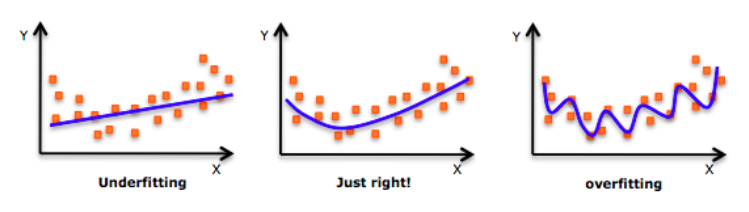
정규화라는 단어가 가지는 의미는 정상화라는 말과 같다. [어떠한 오류나 비정상적인, 패턴이 없는] 상태에서 [정상적인 상태, 일정한 규칙을 가진]상태로 상태를 변화시키는 것이 정규화이다. 정규화가 실제로 수행되는 경우에는 굉장히 다양한 종류들이 있다. 흔하게 볼 수 있는 정규화로는 데이터베이스에서의 정규화, 통계학적 정규화, 머신러닝/딥러닝 학습에서의 정규화 3가지가 있다. 영어로 보자면 Normalization, Regularization가 될 수 있는데, 모두 한국어로하면 정규화라고 한다. 그래서 어떤 누가와서 정규화가 뭐에요?라고 묻는다면, 어떤 정규화를...말하는거지? 하고 헷갈릴 수 있다. 어느 면접에서 실제로 어떤 정규화를 말하는건지 질문자의 의도를 파악하지 못하고, 쌩뚱맞은 정규화에 대해서 ..