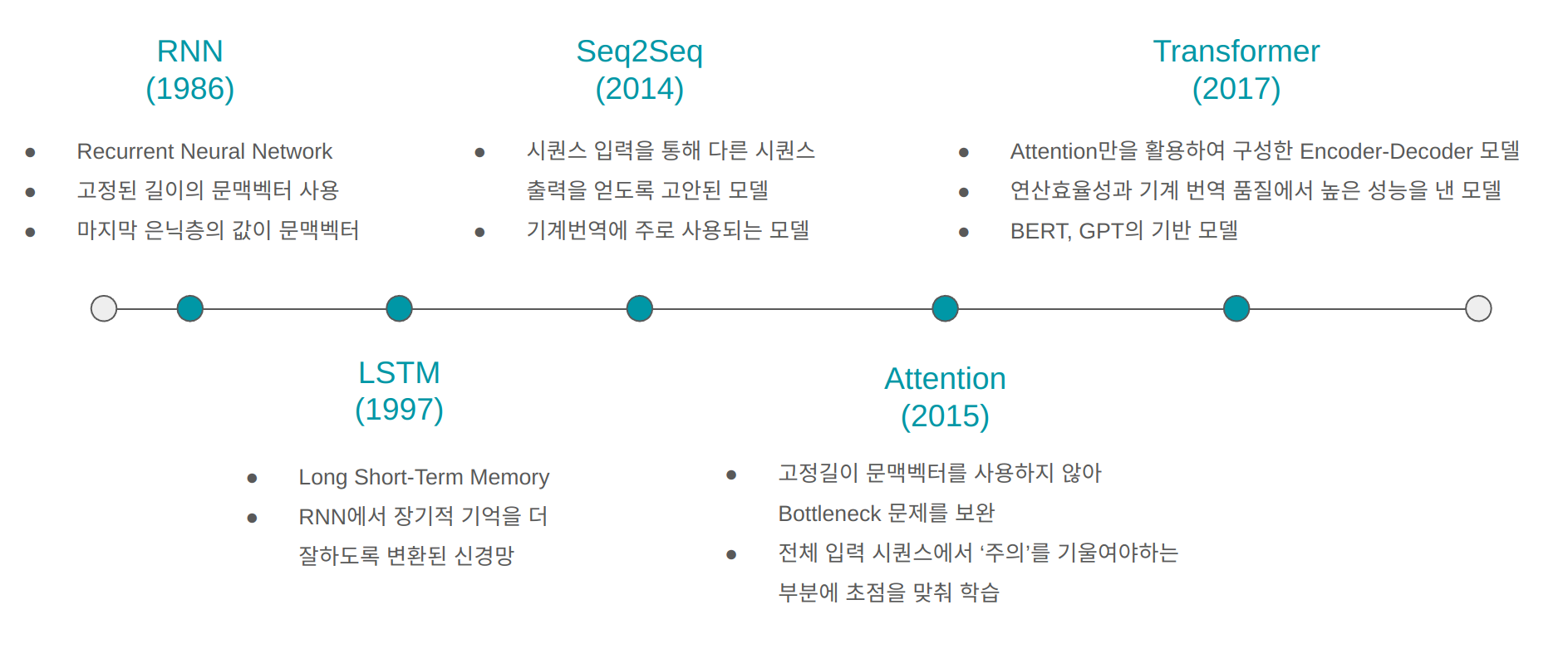
1. RNN (1986) RNN은 시퀀스 데이터를 학습시키기 위해 제안된 신경망 모델로 RNN 기법이 처음으로 제안된 논문은 아래와 같다. 이 논문을 기틀로 RNN 연산을 거치는 신경망모델에 대한 수많은 연구가 수행되었다. Learning representations by back-propagationing errors (pdf 보기) 2. LSTM (1997) LSTM은 RNN의 은닉층에서 계산되는 연산을 변형시켜 장기적 기억을 더 잘하도록 고안된 신경망 모델이다. 처음으로 LSTM 매커니즘이 제안된 논문은 아래와 같다. Long Short-Term Memory 최종적으로 자리잡은 RNN과 LSTM에 대한 개념은 아래의 논문에서 확인할 수 있다. Fundamentals of Recurrent Neura..