EDA는 데이터를 잘 이해하기 위해서 꼭 필요한 과정으로, 일반적으로 시계열 예측 모델을 생성하기 전에 인사이트를 얻기위해 주로 수행하게 된다. 이번 글에서는 EDA의 전반적인 절차와 구체적인 방법들에 대해 자세히 다루어보려 한다.
보편적인 EDA 과정은 세가지 분류로 나누어볼 수 있다.
- Data Description (ex. 변수 설명, 통계량 요약 등)
- Cleaning (ex. 전처리, 결측치 처리 등)
- Visualization (ex. 그래프 시각화)
* 해당 글은 캐글의 Time Series Prediction Tutorial with EDA 를 참고하여 작성되었습니다. 코드와 데이터에 구체적인 사항은 원문을 읽어보시길 바랍니다.
보통 시계열 데이터들은 csv (excel) 파일로 저장된다. 따라서, EDA를 하기 전에 pandas와 같은 패키지를 통해 데이터를 dataframe 형태로 로드하게 된다. 로드에 성공한 뒤 해당 dataframe 데이터를 어떻게 분석할지가 EDA과정이다.
import pandas as pd
# dataframe
df = pd.read_csv(file_path)
Data Description
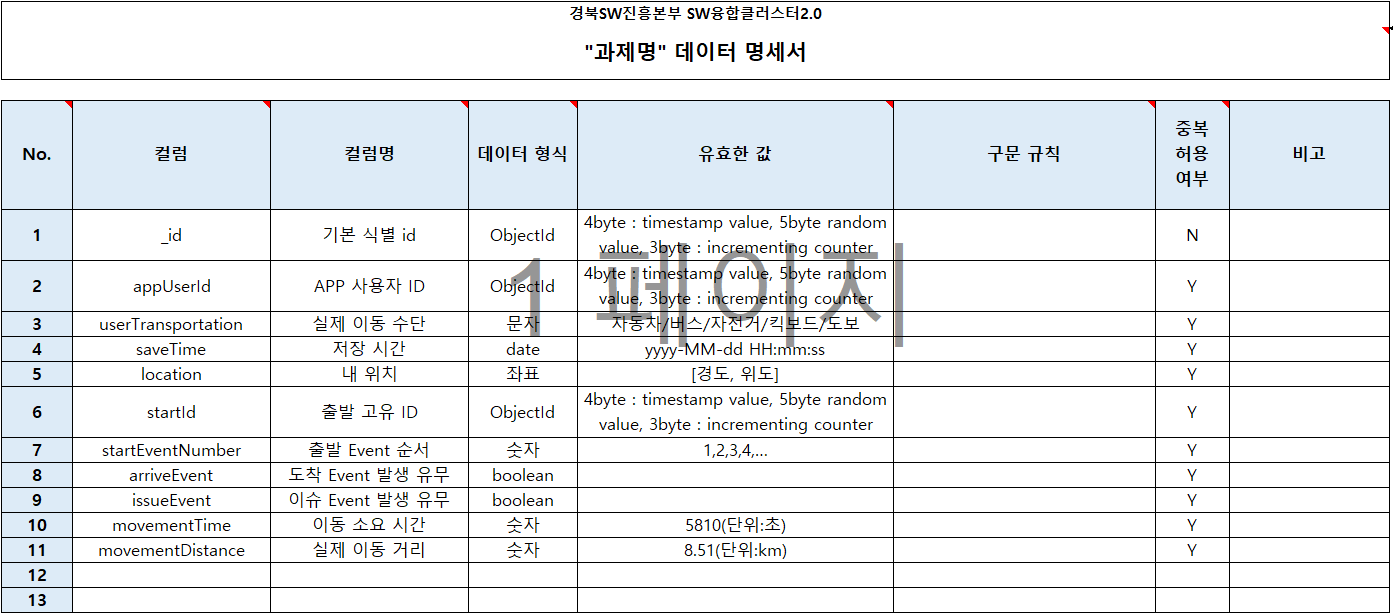
아래의 예시는 제 2차 세계대전의 도시공습에 대한 데이터이다. 데이터에는 columns=features(변수) 에 대한 값들만 존재하기 때문에 데이터 명세서의 일부로 변수에 대한 설명을 나열하여 데이터를 파악하기 쉽도록 한다.

국내 데이터는 보통 데이터 명세서로 아래와 같은 표를 활용하여 문서파일을 따로 제공하는것이 보편적이다.
이와 더불어 pandas 패키지에서 제공하는 데이터 통계량 및 정보에 대해 요약해주는 함수가 있다.
# 데이터 명세
df.info()
# 데이터 요약통계
df.describe()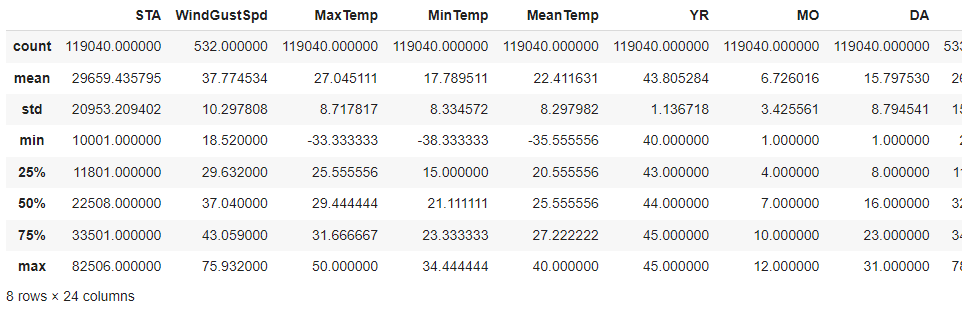
이외에도 pandas에서 지원되는 함수는 sum(), var(), std(), unique(), mode(), corr() 등이 있다.
Data Cleaning
결측치 처리
실제 데이터에서는 모든 순간, 모든 변수에 대해 데이터를 수집하기란 굉장히 어렵다. 그렇기 때문에 결측치가 발생하는데, Data Cleaning작업에서 가장 기초적인 부분이 이러한 결측치를 제거해주는 작업이다.
원하는 columns, row 값만 남기기
결측치 이외에도 데이터 분석에 불필요한 데이터가 있다. 변수 자체가 불필요하여 columns를 제거해줄 수도 있고, 특정 값을 가진 row데이터를 제거해줄 수도 있다.
예시코드를 보자.
# drop countries that are NaN
df = df[pd.isna(df.Country)==False]
# drop if target longitude is NaN
df = df[pd.isna(df['Target Longitude'])==False]
# Drop if takeoff longitude is NaN
df = df[pd.isna(df['Takeoff Longitude'])==False]
# drop unused features
drop_list = ['Mission ID','Unit ID','Target ID','Altitude (Hundreds of Feet)','Airborne Aircraft',
'Attacking Aircraft', 'Bombing Aircraft', 'Aircraft Returned',
'Aircraft Failed', 'Aircraft Damaged', 'Aircraft Lost',
'High Explosives', 'High Explosives Type','Mission Type',
'High Explosives Weight (Pounds)', 'High Explosives Weight (Tons)',
'Incendiary Devices', 'Incendiary Devices Type',
'Incendiary Devices Weight (Pounds)',
'Incendiary Devices Weight (Tons)', 'Fragmentation Devices',
'Fragmentation Devices Type', 'Fragmentation Devices Weight (Pounds)',
'Fragmentation Devices Weight (Tons)', 'Total Weight (Pounds)',
'Total Weight (Tons)', 'Time Over Target', 'Bomb Damage Assessment','Source ID']
df.drop(drop_list, axis=1,inplace = True)
df = df[ df.iloc[:,8]!="4248"] # drop this takeoff latitude
df = df[ df.iloc[:,9]!=1355] # drop this takeoff longitude
# what we will use only
df = df.loc[:,["WBAN","NAME","STATE/COUNTRY ID","Latitude","Longitude"] ]- 결측치 처리 : pandas의 isna 함수로 특정 컬럼의 값이 결측치인지 아닌지에 대해 bool값을 리턴해준다. 해당 코드에서는 array가 인풋으로 들어갔기때문에 array의 모든 값에 대해 true, false를 array형태로 리턴해준다.
- row 데이터 제거 : 이후 df [ condition ] 과 같은 문법으로 condition에 맞는 df의 row들만 추출해낼 수 있다.
- columns(변수) 제거 : df.drop 함수로 사용하지 않는 feature들에 대해서 제거해줄 수 있다.
- df.iloc[row_index, column_index] 로는 특정 index(숫자)를 통해 row, column 을 추출할 수 있다. (df.loc은 행과 열의 이름으로 추출함)
이러한 클리닝 작업을 끝내고 다시 data description과정을 거치고, 데이터를 시각화하는 것으로 데이터를 파악하게 된다.
Visualization
EDA과정에서 주로 시각화하는 정보는 데이터의 feature마다 어떤 값들이 있고, 그 값들의 빈도수(frequency) 및 분포에 대한 것이다. 시각화 그래프의 형태로는 히스토그램, 산점도, 도표 등이 있다.
빈도수 파악
: 하나의 column에 대한 값의 분포를 알아봅니다.
# country
print(df['Country'].value_counts())
plt.figure(figsize=(22,10))
sns.countplot(df['Country']) # 히스토그램 형태 그래프
plt.show()
공간정보 시각화 (지도)
longitude, latitude와 같은 위도, 경도 정보가 있는경우에는 아래와 같이 plotly 라이브러리를 이용해서 지도에 시각화를 할 수도 있다.
import plotly.graph_objs as go
data = [dict(
type='scattergeo',
lon = aerial['Takeoff Longitude'],
lat = aerial['Takeoff Latitude'],
hoverinfo = 'text',
text = "Country: " + aerial.Country + " Takeoff Location: "+aerial["Takeoff Location"]+" Takeoff Base: " + aerial['Takeoff Base'],
mode = 'markers',
marker=dict(
sizemode = 'area',
sizeref = 1,
size= 10 ,
line = dict(width=1,color = "white"),
color = aerial["color"],
opacity = 0.7),
)]
layout = dict(
title = 'Countries Take Off Bases ',
hovermode='closest',
geo = dict(showframe=False, showland=True, showcoastlines=True, showcountries=True,
countrywidth=1, projection=dict(type='Mercator'),
landcolor = 'rgb(217, 217, 217)',
subunitwidth=1,
showlakes = True,
lakecolor = 'rgb(255, 255, 255)',
countrycolor="rgb(5, 5, 5)")
)
fig = go.Figure(data=data, layout=layout)
iplot(fig)
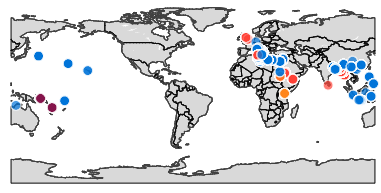
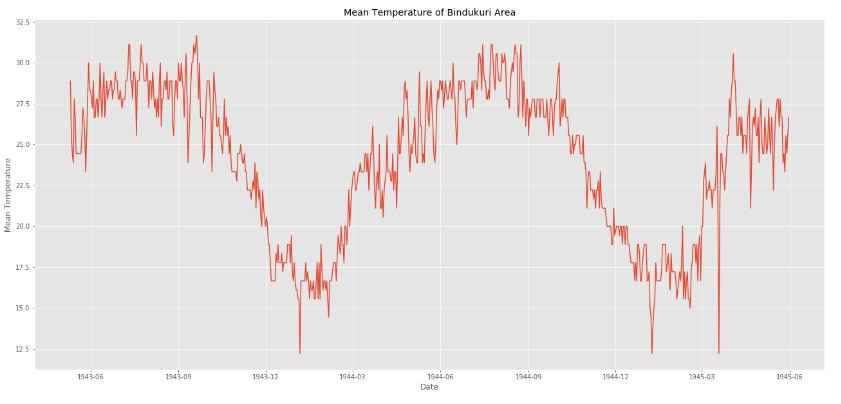
시계열 그래프
시계열 그래프에서 가장 중요한 것은 datetime형태의 날짜 컬럼을 x축에 두고, 시간 흐름에 따라 기록된 value를 y축에 입력하여 시각화하는 것이다. 캐글의 예시 코드를 보자.
import matplotlib.pyplot as plt
weather_station_id = weather_station_location[weather_station_location.NAME == "BINDUKURI"].WBAN
weather_bin = weather[weather.STA == 32907]
weather_bin["Date"] = pd.to_datetime(weather_bin["Date"])
plt.figure(figsize=(22,10))
plt.plot(weather_bin.Date,weather_bin.MeanTemp)
plt.title("Mean Temperature of Bindukuri Area")
plt.xlabel("Date")
plt.ylabel("Mean Temperature")
plt.show()- 전처리 1 : 간단한 전처리를 통해 확인하고자 하는 데이터만을 추출합니다.
- 전처리 2 : pd.to_datetime으로 string형태로 되어있는 값을 datetime type으로 값을 변환해줍니다.
- 시각화 : plt.plot(x,y) - x축에 Date컬럼을 y축에는 평균기온 값이 있는 MeanTemp컬럼을 입력해줍니다.
아래의 코드로 원하는 날짜만을 추출하여 시각화시킬수도 있습니다.
aerial = pd.read_csv("../input/world-war-ii/operations.csv")
aerial["year"] = [ each.split("/")[2] for each in aerial["Mission Date"]]
aerial["month"] = [ each.split("/")[0] for each in aerial["Mission Date"]]
aerial = aerial[aerial["year"]>="1943"]
aerial = aerial[aerial["month"]>="8"]
aerial["Mission Date"] = pd.to_datetime(aerial["Mission Date"])
다음 글에서는 EDA의 두번째 내용으로 좀 더 구체적으로 시계열 데이터에 특화된 EDA방법에 대해서 알아보겠습니다.
감사합니다.
'AI > Time Series' 카테고리의 다른 글
| 시계열 데이터 분석하기 : 데이터의 정상성 (3) | 2024.03.05 |
|---|---|
| 시계열 데이터 EDA(Exploratory Data Analysis) 하기 (2) (0) | 2024.02.22 |
| 시계열 데이터 기초 용어, 이론, 특징 알아보기 (0) | 2024.02.18 |