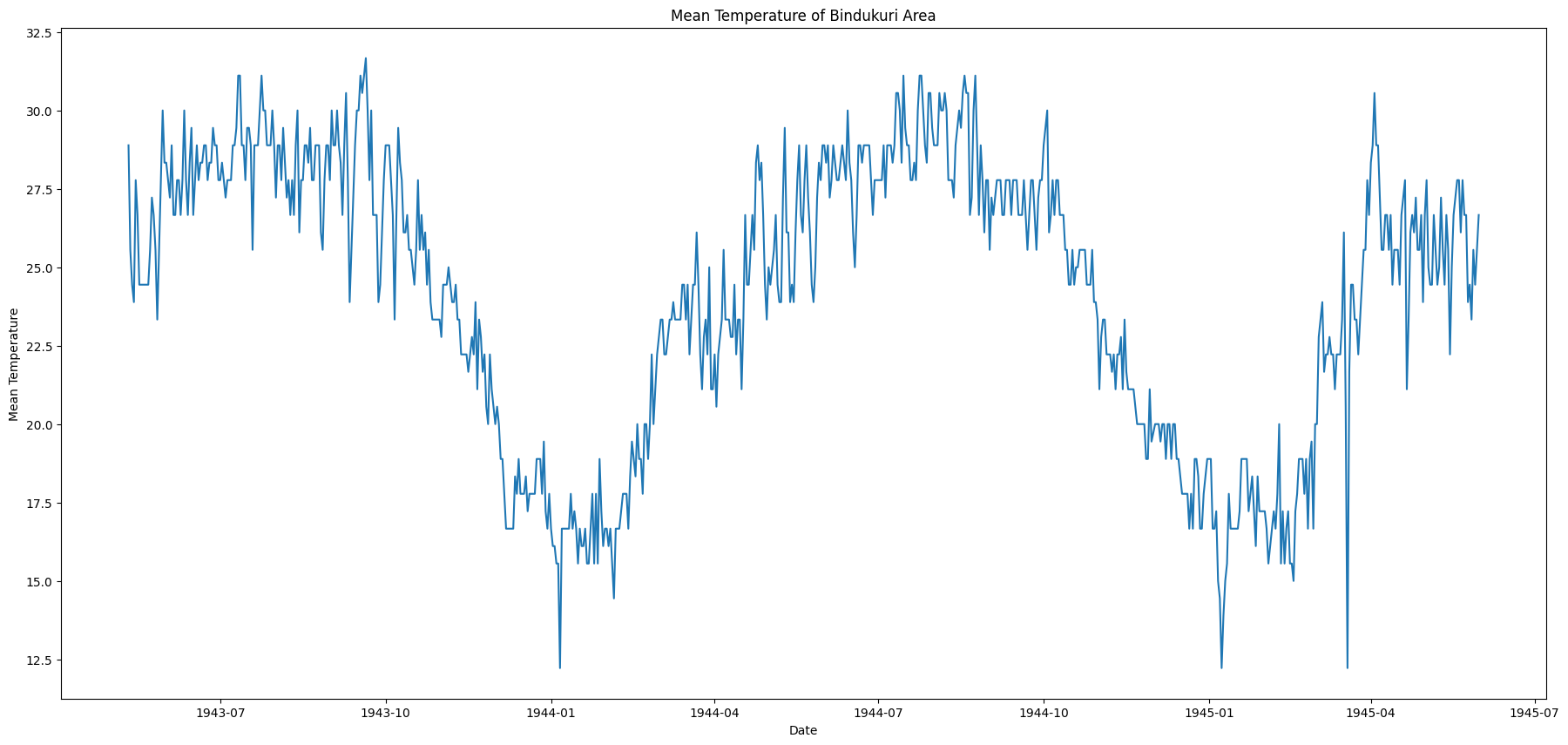
시계열 데이터를 분석하는 목적은 아래와 같습니다. 시간에 따른 데이터의 패턴을 파악하기 위함. (ex. 계절성, 추세와 같은 변동성 + 자기상관성 등) 분석된 패턴에 기반한 예측 모형을 통해 Forcasting(시계열 예측)하기 위함. 시계열 분석은 쉽게 말하면 과거의 값의 패턴을 분석해서 미래의 값을 추정하기 위한 것입니다. 이를 위해 가장 기본적인 것은 시계열 데이터 가 정상성을 유지해야한다는 것입니다. Why? 왜 정상성을 유지해야하는가?? 왜 잡음만 있는 상태에서 시계열을 예측해야하는가? 먼저 이론적으로는 정상성을 띈다는 말은 시계열 데이터가 시점과 상관없이 일정한 평균과 분산을 가진다는 의미이다. 어떤 시점에 데이터를 측정해도 일정한 변동폭(정규분포를 따르는 잡음)을 가진다는 의미입니다. 이를 ..