Pandas 라이브러리로 이러한 데이터를 어떻게 조작할 수 있는지 그 모든 함수들을 모아보기로 하자.
(차근히 업데이트 예정)
보편적으로 Pandas에서 취급하는 데이터 형태는 행과 열이 있는 표 형태인 Tabular Data이다.
이런 2차원(2-dimensional) 데이터를 pandas에서는 "데이터프레임(DataFrame)"이라고 부른다.
그 외에도 아래와 같은 데이터 형태도 존재한다.
Series : 1차원 데이터; DataFrame에서 하나의 행 또는 열만 추출하는 경우
Panel : 3차원 데이터
Pandas 설치
pip install pandas원하는 환경에 pip으로 pandas를 간단히 설치 후, (conda로도 가능함 - how to install pandas 라고 구글링하세요.)
임포트 해준다.
import pandas as pd # 보편적으로 pd라는 닉네임으로 줄여서 씀
데이터 생성
1) 직접 데이터프레임을 생성 (How to create DataFrame)
# 변수 네이밍은 데이터프레임의 약자인 df를 보편적으로 사용함
df = pd.DataFrame(data=None, index=None, columns=None, dtype=None, copy=None)- data = ndarray (structured or homogeneous), Iterable, dict, or DataFrame
- index = Index or array-like
- columns = Index or array-like
- dtype = data type (default None)
- copy = bool(True or False) or None
2) List형 변수를 데이터프레임으로 생성 (How to create DataFrame from Lists)
list1 = [50,48,22,25]
list2 = ['Dad', 'Mom', 'Sister', 'Me']
df = pd.DataFrame(list(zip(list1, list2)), columns=['Family','Age'])
df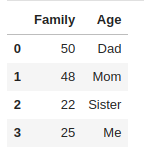
데이터 불러오기
1) 엑셀파일을 불러와서 데이터프레임을 생성 (참고링크)
df = pd.read_excel(io, sheet_name=0, *, header=0, names=None, index_col=None,
usecols=None, dtype=None, engine=None, converters=None, true_values=None,
false_values=None, skiprows=None, nrows=None, na_values=None, keep_default_na=True,
na_filter=True, verbose=False, parse_dates=False, date_parser=_NoDefault.no_default,
date_format=None, thousands=None, decimal='.', comment=None, skipfooter=0,
storage_options=None, dtype_backend=_NoDefault.no_default)- 많은 매개변수들이 있지만 기본적으로는 경로(io), 시트명(sheet_name) 파라미터만 설정해줘도 될 것이다.
(시트가 하나뿐인 파일의 경우에는 sheet_name을 생략해줘도 된다.)
▼ 세부 파라미터는 접은 글로
# sheet_name : str, int, list, or None, default 0
# header : int, list of int, default 0
- header에는 int, list of int로 파라미터를 설정하여, 몇번째 row에 헤더가 있는지 설정하는 용도
- header가 0이면 파일의 0번째 row를 헤더로 불러오겠다는 의미.
- header가 None이면 헤더가 없는 파일을 불러오겠다는 의미.
# names : array-like, default None
- 칼럼의 이름을 지정하는 용도. header=None일 때, 자주 사용됨.
# index_col : int, list of int, default None
- row에 대한 인덱스 칼럼이 있는 경우, 그 칼럼이 몇번째 column 인덱스에 있는지 설정하는 용도
* 참고 : 첫 실행 시, 아래와같은 에러가 뜰 수도 있다.
(pandas를 지원하는 openpyxl 라이브러리가 설치되지 않을 때 뜨는 에러이므로 바로 설치해주면 에러가 나지 않는다.)

2) csv파일 불러오기
df = pd.read_csv(path, sep=',')
데이터 편집
1) 데이터프레임에 컬럼(Column) 추가하기
- List형 데이터를 기존의 데이터프레임에 추가하는 방법
- values_list라는 리스트의 값들을 df 데이터프레임에 "NewColumnName"이라는 칼럼으로 추가한다는 의미.
df["New_Column_Name"]=values_list2) 여러 개의 데이터프레임 합치기
- axis를 주의하세요! default 는 0으로 row로 추가되고, 1일 경우에는 column에 추가된다.
- dataframe 객체들을 list에 싸야한다는 것을 주의하세요!
- document
pandas.concat — pandas 2.0.3 documentation
If True, do not use the index values along the concatenation axis. The resulting axis will be labeled 0, …, n - 1. This is useful if you are concatenating objects where the concatenation axis does not have meaningful indexing information. Note the index
pandas.pydata.org
total_df = pd.concat([df1, df2, df3], axis=0)
데이터 저장하기
1) csv파일로 저장하기
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.to_csv.html
DataFrame.to_csv(path_or_buf=None, sep=',', na_rep='', float_format=None,
columns=None, header=True, index=True, index_label=None,
mode='w', encoding=None, compression='infer', quoting=None,
quotechar='"', lineterminator=None, chunksize=None,
date_format=None, doublequote=True, escapechar=None,
decimal='.', errors='strict', storage_options=None)수많은 파라미터들이 있지만 간단하게 아래의 정도만 기억해둬도 충분하다.
# output.csv라는 파일명으로 df를 저장하고 구분자는 쉼표(,)로 하겠다.
df.to_csv('output.csv', sep=',')2) excel파일로 저장하기 (.xlsx)
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.to_excel.html
DataFrame.to_excel(excel_writer, sheet_name='Sheet1', na_rep='', float_format=None,
columns=None, header=True, index=True, index_label=None,
startrow=0, startcol=0, engine=None, merge_cells=True,
encoding=_NoDefault.no_default, inf_rep='inf',
verbose=_NoDefault.no_default, freeze_panes=None,
storage_options=None)여기서는 더 간단하게, 이렇게만 해도 충분하다.
df.to_excel('output.xlsx')'Programming > python' 카테고리의 다른 글
| 파이썬 원하는대로 리스트 정렬하기 Python sort(), sorted() (0) | 2022.12.24 |
|---|---|
| [프로그래머스] 파이썬 Python 점의 위치 구하기 | List Tuple Boolean Indexing (0) | 2022.12.24 |
| 파이썬 - 출력 텍스트에 색상넣는 방법 | print() function with colored text in python (0) | 2022.11.17 |
| Python에서 __future__ 모듈의 기능 (0) | 2022.11.14 |
| Markdown Cheatsheet - Jupyter Notebook / Lab 마크다운모음집 (0) | 2022.10.24 |