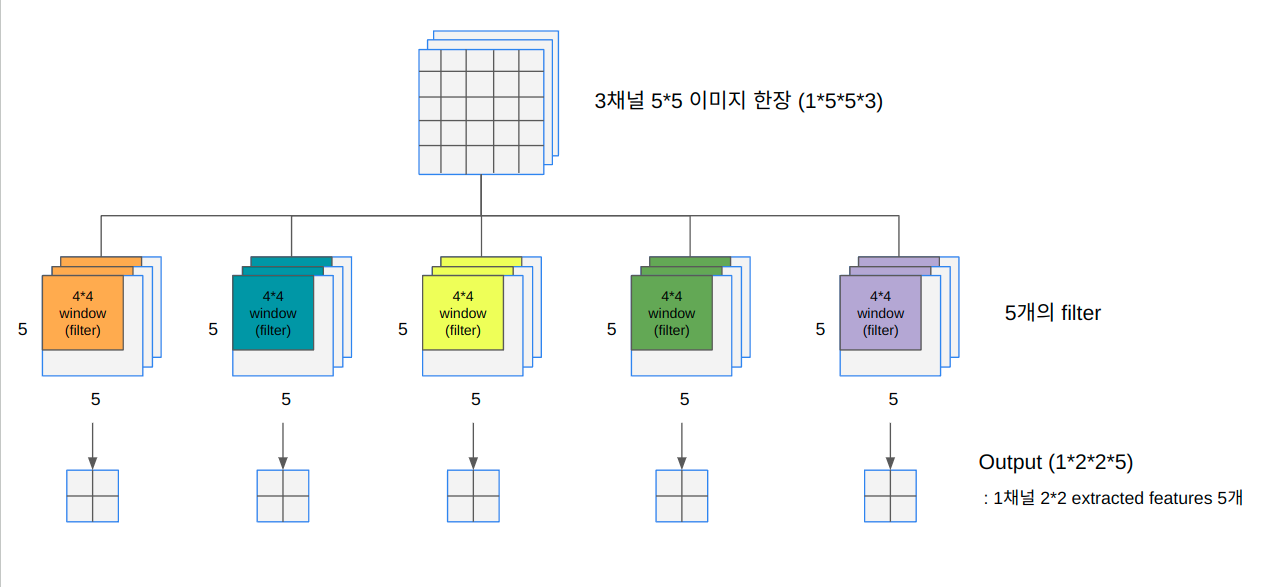
Tensorflow, Numpy - squeeze()와 flatten()의 차이
Tensorflow(Keras)에서는 다양한 연산을 해줄 수 있는함수들을 Layer의 형태로 제공해주고 있다. (ex. Dense, Convolution, Pooling,,,) 어떤 값들이 Layer를 통해서 나오는 Output은 텐서 형태로 그 결과물에 대해 추가적인 변형을 주고싶을 때는 해당 객체를 numpy형태로 변환해주어야한다. 그 과정은 아래의 MaxPooling2D 레이어를 거친 결과물로 예시를 들어 코드를 작성한 것에서 pooled_max.numpy()부분이다. import numpy as np import tensorflow as tf from tensorflow.keras.layers import MaxPooling2D N, n_H, n_W, n_C = 1, 5, 5, 1 f, s = 2..