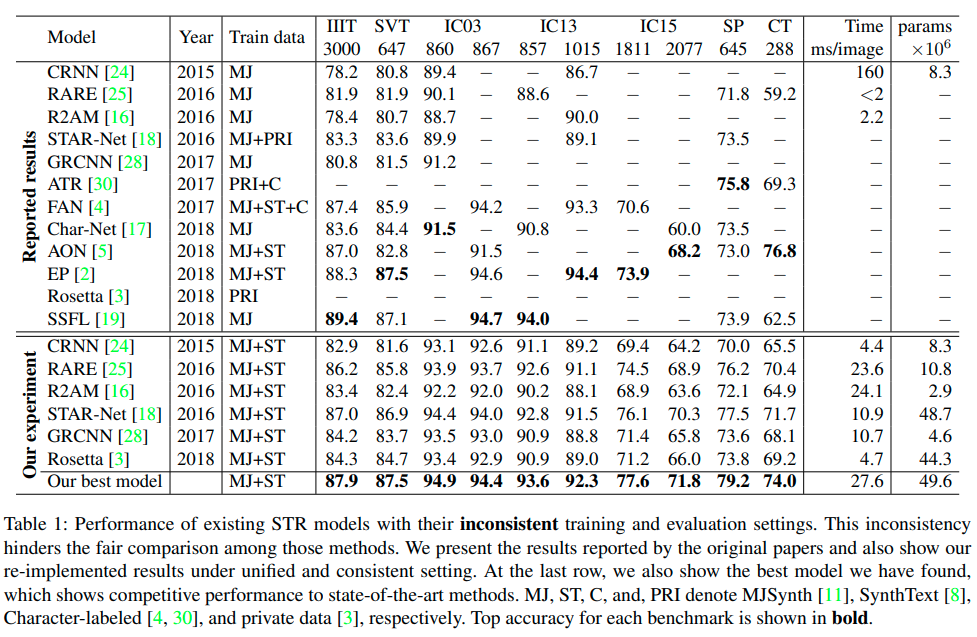
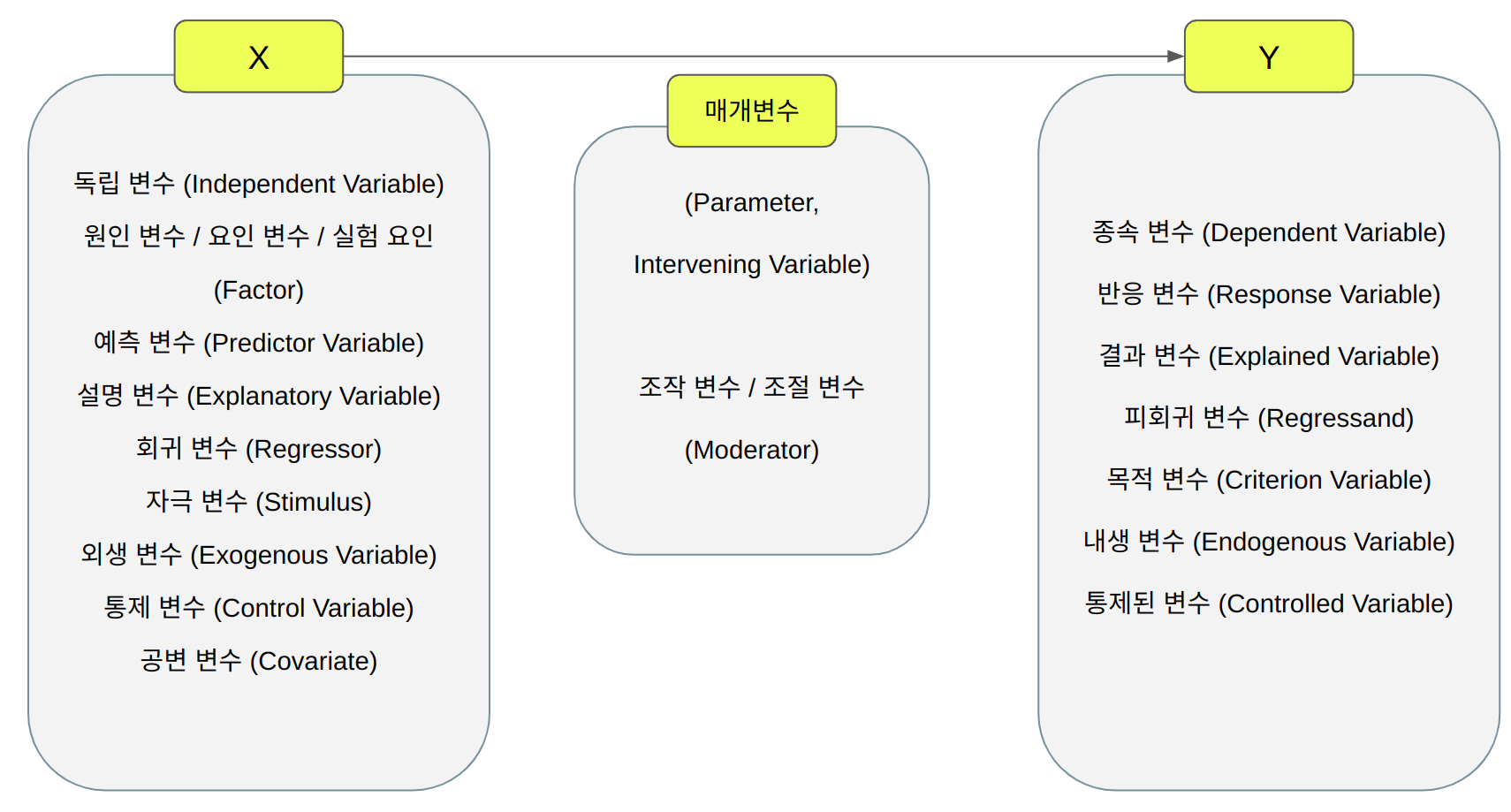
개요 STR(Scene Text Recognition) 분야에서 기술의 한계를 깨고 있다고 주장되는 모델들은 각자 다른 학습/평가 데이터셋을 사용해서 비일관적이다. 이에 대해 전반적으로 공평한 비교가 어렵기 때문에 해당 논문에서는 1) 비일관적인 평가 결과의 차이를 확인하고, 2) 통합적인 STR 프레임워크를 제안한다. 마지막으로는 3) 모듈마다의 성능(정확도, 속도, 메모리)을 분석하여 명확히 비교한다. 원문 보기 : https://arxiv.org/abs/1904.01906 What Is Wrong With Scene Text Recognition Model Comparisons? Dataset and Model Analysis Many new proposals for scene text recogn..