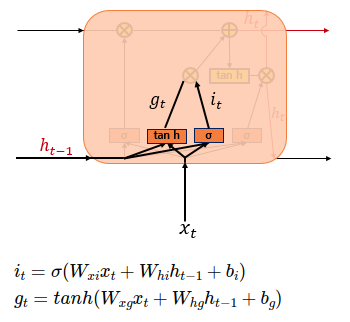
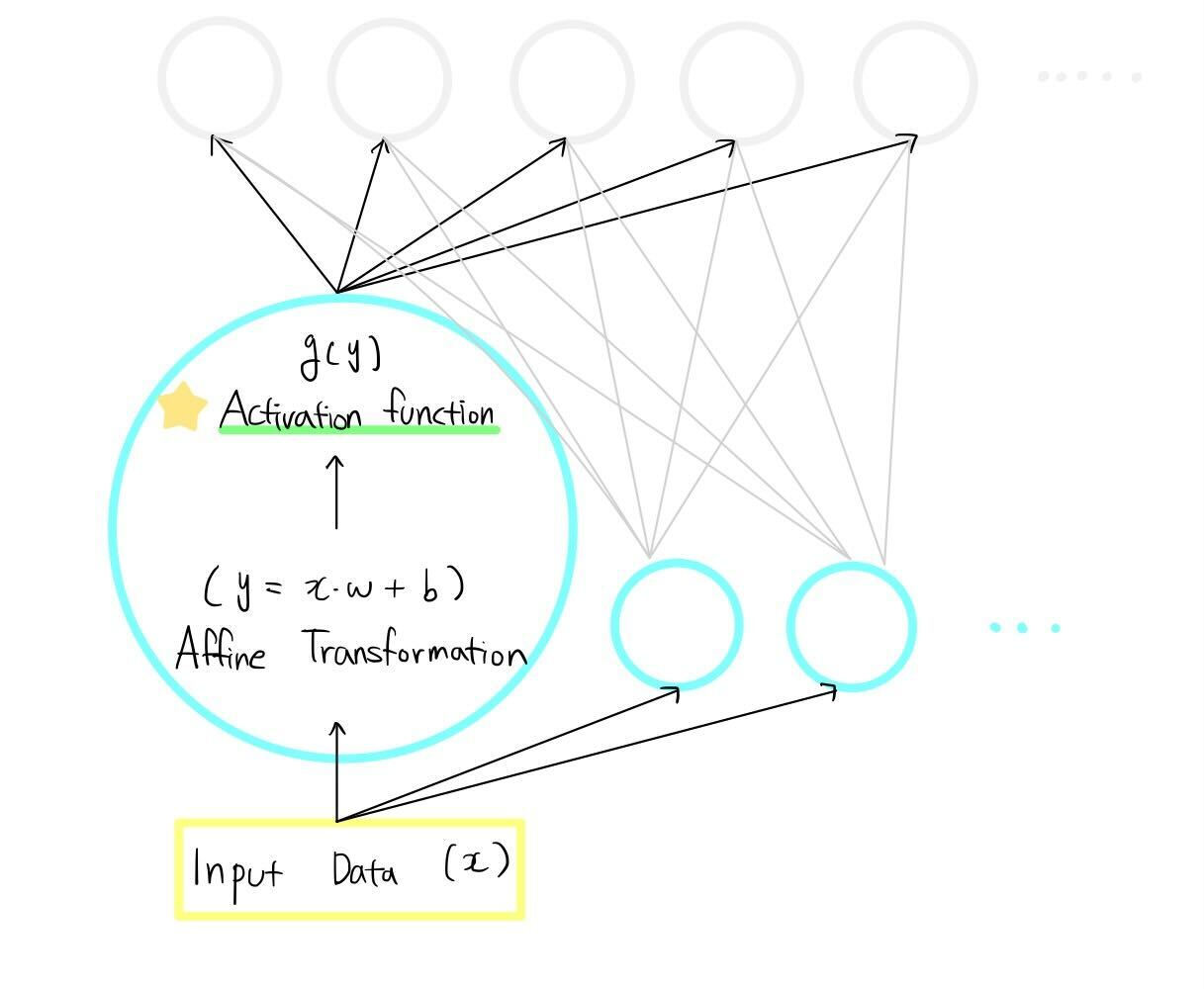
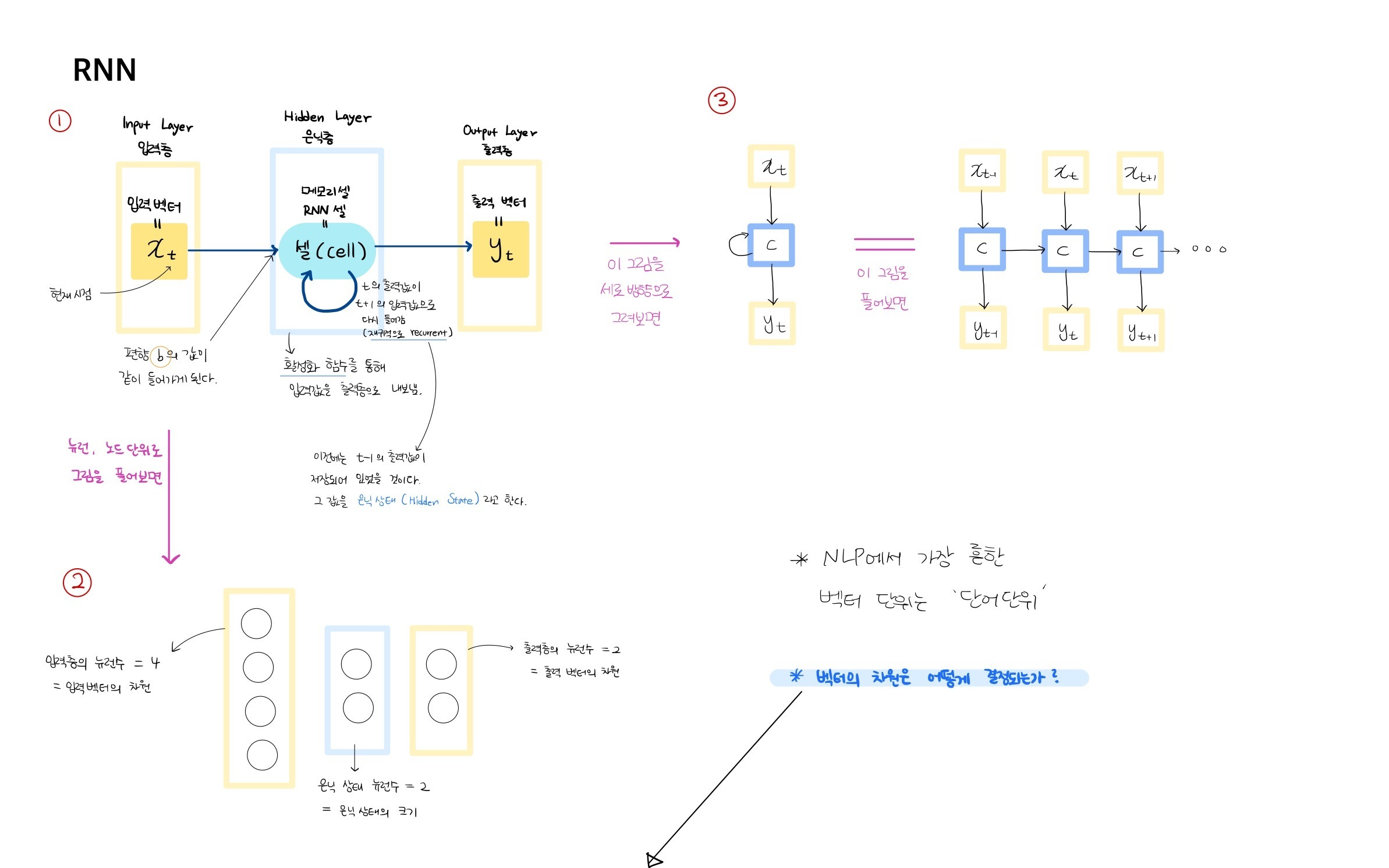
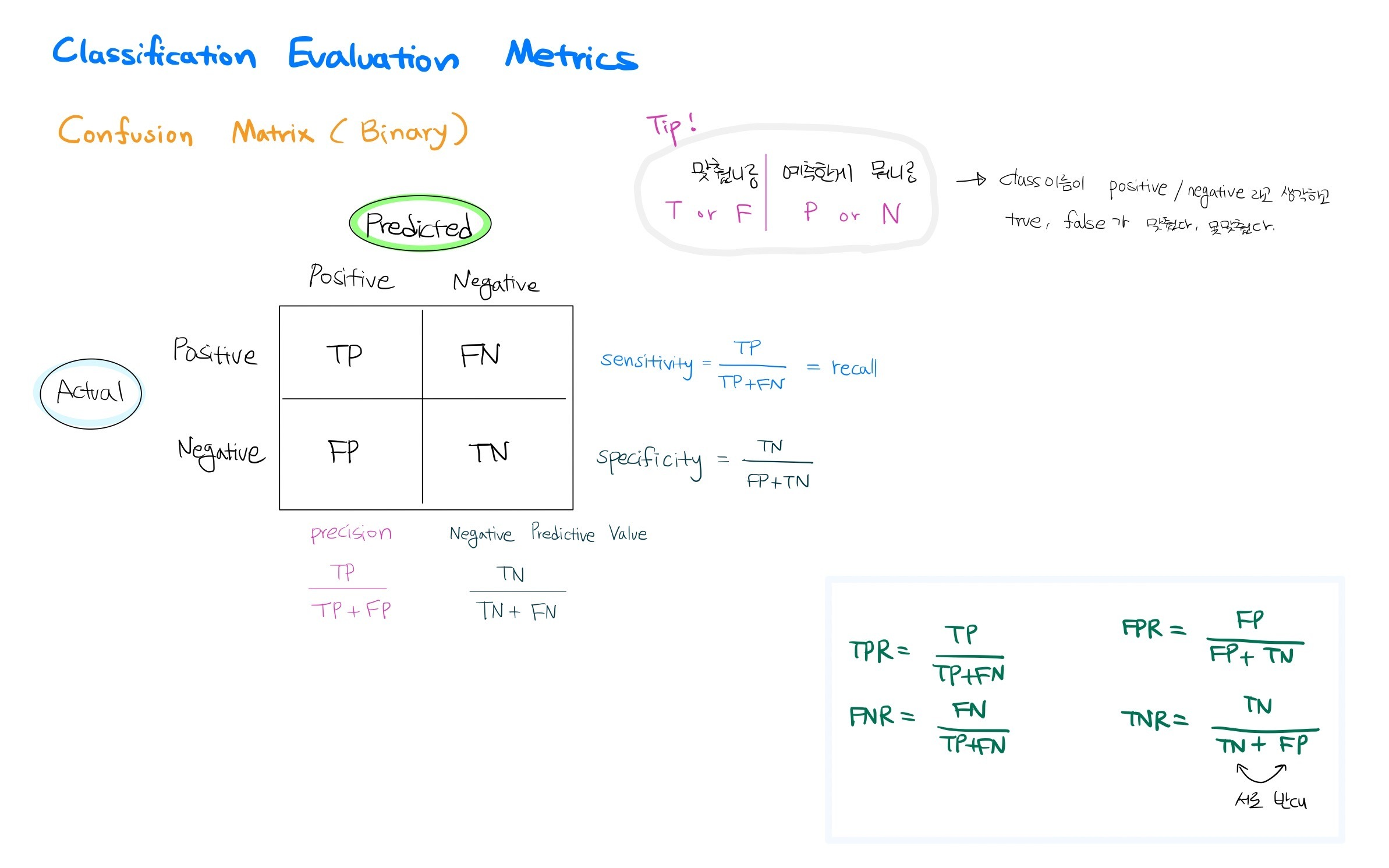
이 글을 읽기 전에 해당 내용은 08-02 장단기 메모리(Long Short-Term Memory, LSTM) - 딥 러닝을 이용한 자연어 처리 입문 을 보고 공부한 내용입니다. 잘못된 부분이 있다면 댓글 부탁드립니다. 아래의 내용을 보기 전에 RNN을 먼저 공부하고 오시는 것을 추천드립니다! https://kyull-it.tistory.com/139 RNN(Recurrent Neural Network) 순환신경망 공부하기 08-01 순환 신경망(Recurrent Neural Network, RNN) - 딥 러닝을 이용한 자연어 처리 입문 글을 참고하여 공부한 내용을 정리하였습니다. RNN은 Input값과 Output값을 Sequence 단위로 끊어서 처리하는 Sequence Model kyull-it...